Sécuriser et maintenir n8n en production

Deuxième volet de la série "n8n en production : le guide complet"
Un workflow n8n qui fonctionne en test n'est pas forcément prêt pour la production. Les problèmes apparaissent ailleurs : sécurité des webhooks, sauvegarde des workflows, et capacité à reconstruire l'instance quand tout casse.
Le premier article de cette série couvrait la gestion d'erreurs. Celui-ci traite de ce qui vient avant et autour. Par défaut, un webhook n8n est ouvert au monde, vos workflows n'ont pas de version control, et si votre VPS crashe sans backup, c'est un rebuild complet. On va aller plus loin que "mettez un mot de passe sur votre webhook".
Webhooks : trois couches de protection
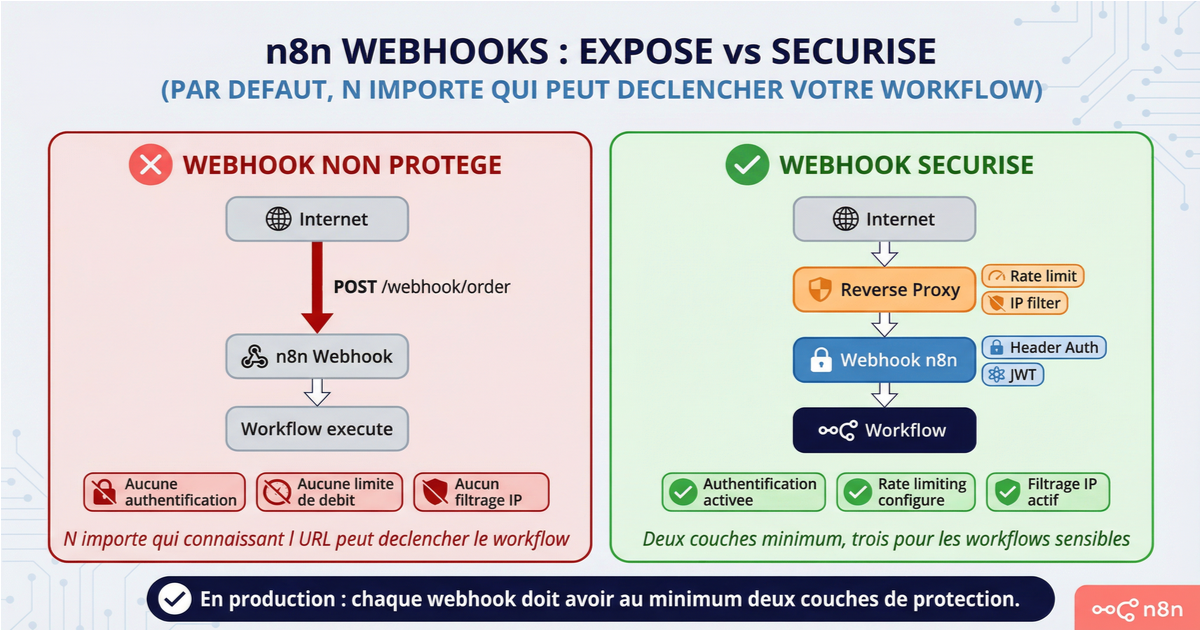
Par défaut, un webhook n8n est public. N'importe qui connaissant l'URL peut envoyer une requête et déclencher votre workflow. C'est le comportement par défaut sur n8n comme sur Make, Zapier ou tout autre outil d'automatisation. La différence, c'est que n8n vous donne les moyens de verrouiller ça proprement.
L'authentification basique (Basic Auth) ouvre une fenêtre de connexion username/password quand quelqu'un accède à l'URL. C'est adapté aux cas où un humain interagit avec le webhook — un formulaire protégé, une page de confirmation. En machine-to-machine, c'est inutilisable. Point important : si les identifiants ne correspondent pas, n8n ne déclenche même pas l'exécution du workflow. L'attaquant ne peut pas déduire que l'URL existe, il reçoit juste un refus silencieux.
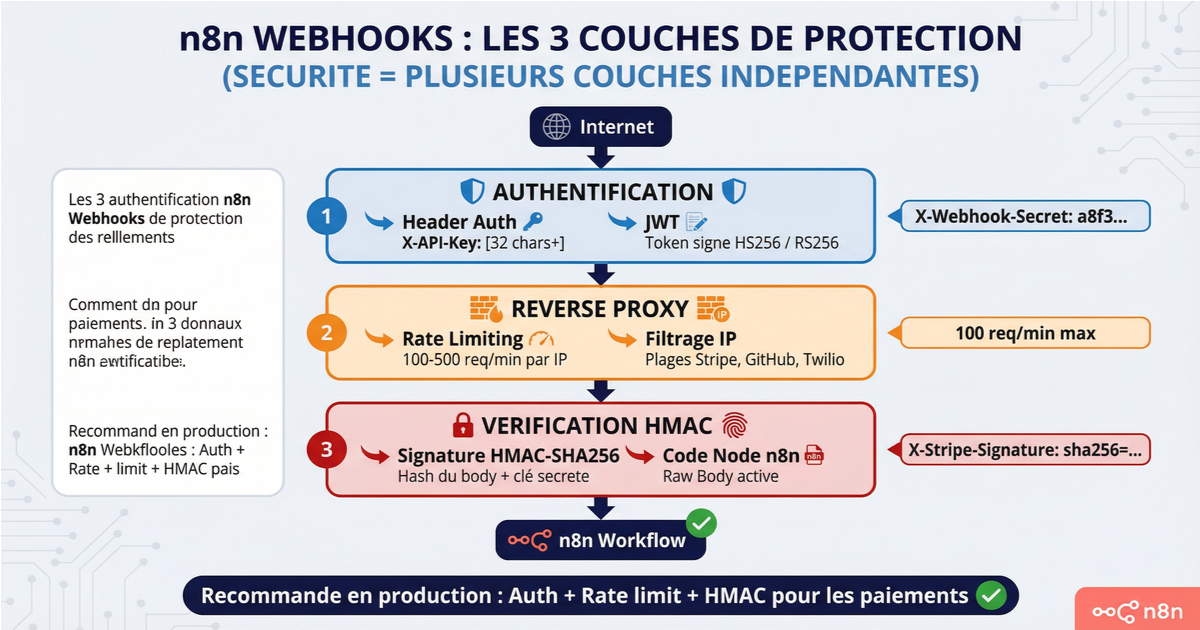
L'authentification par header (Header Auth) est le mécanisme le plus utilisé en production. Vous définissez un nom de header personnalisé et une valeur secrète. Toute requête qui n'inclut pas ce header avec la bonne valeur reçoit un 401. C'est l'équivalent d'une clé API. Utilisez un générateur de mots de passe pour créer une valeur d'au moins 32 caractères avec symboles, et stockez-la dans un gestionnaire de mots de passe ou dans les variables d'environnement de n8n.
L'authentification JWT va un cran plus loin. Le token est signé cryptographiquement avec une passphrase, ce qui signifie que même intercepté en transit, il ne peut pas être forgé sans la clé. Le JWT embarque aussi des claims — des informations sur l'identité et les droits de l'appelant. Utile quand plusieurs systèmes appellent le même webhook avec des niveaux d'accès différents. L'algorithme HS256 est le plus courant. En production, préférez RS256 si vous avez besoin de vérifier le token sans partager la clé privée.
Vérifier l'intégrité du message, pas juste l'identité
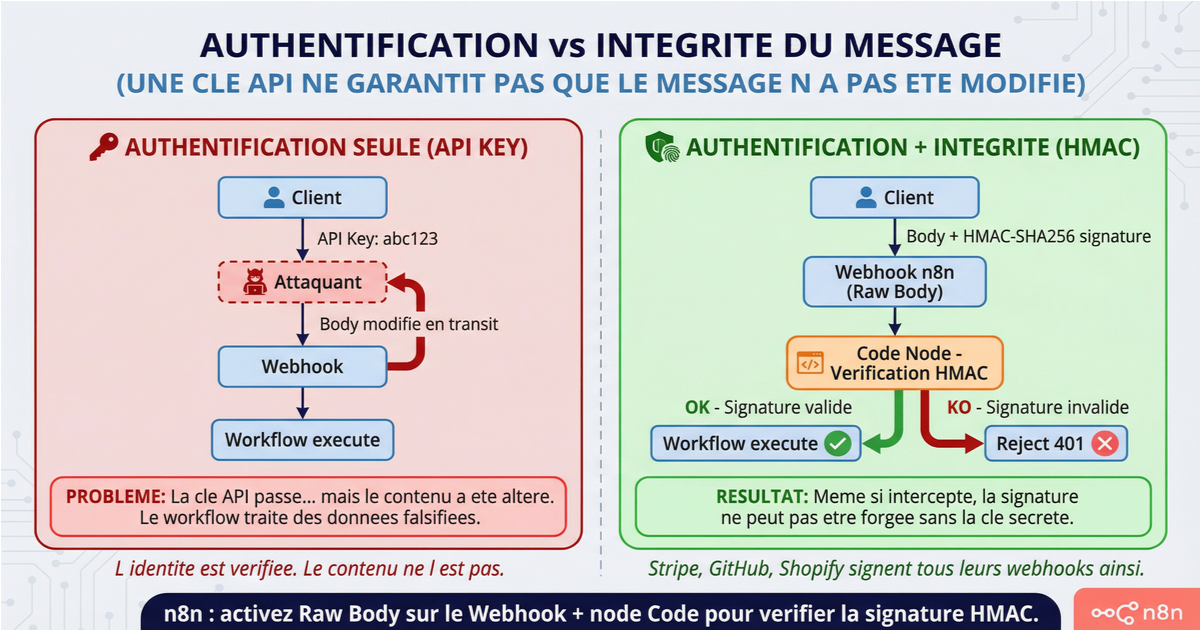
Ces trois méthodes vérifient l'identité de l'appelant. Elles ne vérifient pas l'intégrité du message. La différence est importante : une clé API prouve que le système qui appelle a les droits. La vérification de signature prouve que le contenu de la requête n'a pas été altéré entre l'envoi et la réception.
Les plateformes comme Stripe, GitHub et Shopify signent leurs webhooks avec HMAC-SHA256. Elles calculent un hash du body de la requête avec une clé secrète partagée, et incluent ce hash dans un header. Côté réception, vous recalculez le hash et comparez. Si ça ne matche pas, le message a été falsifié ou ne vient pas du bon émetteur.
n8n ne propose pas de vérification HMAC native sur le node Webhook générique. C'est une feature request active dans la communauté. En attendant, la solution est un node Code placé juste après le Webhook. Activez "Raw Body" dans les options du Webhook pour accéder au body non parsé (nécessaire pour que le calcul HMAC fonctionne), puis utilisez le module crypto de Node.js pour vérifier la signature. Si la vérification échoue, le node Code lève une erreur et le workflow s'arrête.
Pour les intégrations Stripe spécifiquement, le node Stripe Trigger de n8n a récemment ajouté la vérification de signature native. Si vous utilisez le trigger dédié plutôt qu'un webhook générique, la vérification est gérée automatiquement.
Le rate limiting et le filtrage IP
L'authentification ne protège pas contre le volume. Un attaquant peut bombarder votre webhook de requêtes — chaque tentative consomme des ressources serveur et des crédits d'exécution même si elle échoue à l'authentification.
n8n n'a pas de rate limiting intégré au niveau des webhooks. La protection se fait en amont, au niveau du reverse proxy. Nginx permet de configurer un rate limit par IP en quelques lignes. Une limite de 100 à 500 requêtes par minute est raisonnable pour la plupart des webhooks.
Le filtrage IP ajoute une couche supplémentaire quand vous connaissez les adresses des systèmes qui appellent vos webhooks. Stripe, Twilio et GitHub publient leurs plages d'IP. Dans la configuration Nginx, vous pouvez rejeter tout trafic qui ne provient pas de ces plages avant même qu'il atteigne n8n. Le trafic malveillant ne touche jamais votre instance.
La combinaison recommandée en production : authentification par header ou JWT sur le webhook n8n, vérification HMAC pour les webhooks de paiement ou les événements critiques, rate limiting au niveau Nginx, et filtrage IP quand les sources sont connues. Deux couches minimum, trois pour les workflows sensibles.
En résumé — en production, un webhook devrait toujours être protégé par au moins deux couches : authentification (header ou JWT), rate limiting côté reverse proxy, et vérification HMAC pour les événements critiques (paiements, créations de comptes).
Sécuriser les entrées, c'est une moitié du travail. L'autre moitié, c'est de pouvoir tout reconstruire quand quelque chose casse.
Sauvegarder et versionner les workflows
n8n Community Edition n'a pas de version control intégré. L'édition Enterprise propose un source control basique push/pull vers Git, mais pour la majorité des utilisateurs self-hosted, la sauvegarde repose sur ce que vous mettez en place vous-même.
Ce qui doit être sauvegardé
Les workflows évidemment — ce sont des fichiers JSON. Mais aussi les credentials, qui sont chiffrées avec la variable N8N_ENCRYPTION_KEY. Perdre cette clé, c'est perdre l'accès à toutes vos connexions tierces et devoir recréer chaque intégration manuellement. Les variables d'environnement de votre instance font aussi partie du périmètre : configuration PostgreSQL, clé de chiffrement, URL du webhook, paramètres SMTP.
Backup via l'API n8n vers le cloud
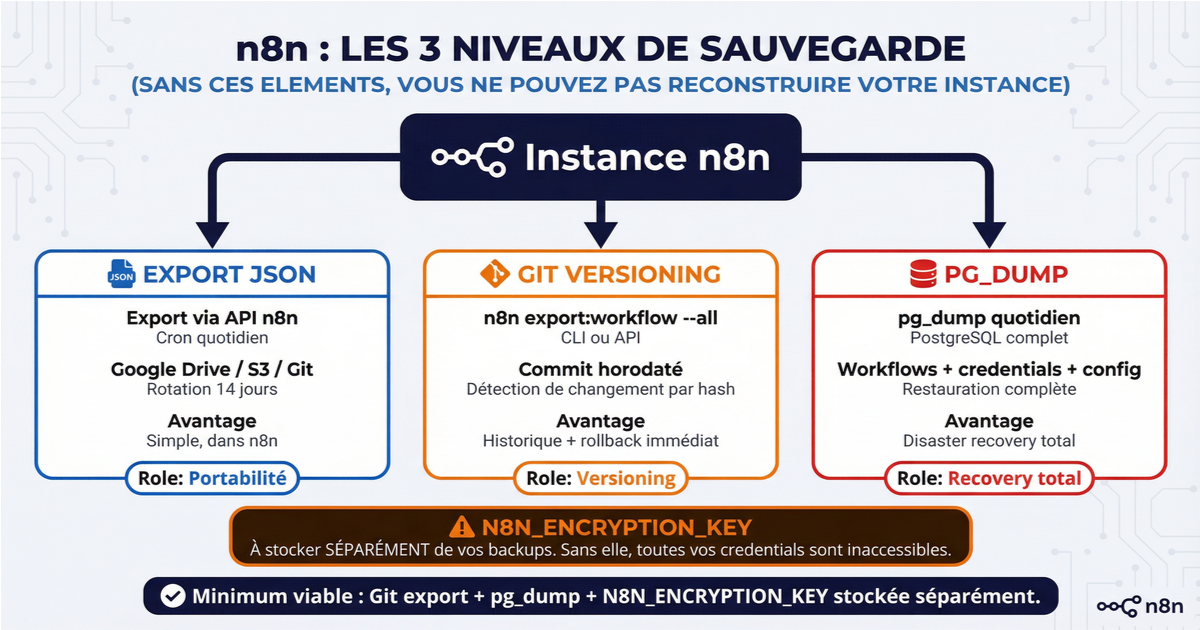
L'approche la plus accessible. Un workflow n8n dédié, déclenché par un cron quotidien, appelle l'API interne pour récupérer la liste de tous les workflows, les convertit en fichiers JSON, et les pousse vers Google Drive, Dropbox ou S3. Avec une rotation automatique qui supprime les backups de plus de 14 jours. C'est le pattern que vous trouverez dans de nombreux templates de la communauté.
L'avantage : tout est géré dans n8n, pas de dépendance externe.
Le risque : si votre instance est hors service, le workflow de backup ne tourne plus non plus. Et cette approche ne sauvegarde ni les credentials ni les variables d'environnement.
Backup vers Git
Même principe d'export via l'API, mais vers un repository GitHub ou GitLab. Le versioning est natif : chaque commit est un snapshot horodaté, vous pouvez comparer deux versions d'un workflow, et le rollback est immédiat. Certains templates ajoutent une détection de changement par hash — le workflow ne commit que si quelque chose a réellement changé, ce qui évite de polluer l'historique.
Pour les instances Docker, une variante plus robuste utilise la CLI n8n directement : n8n export:workflow --all et n8n export:credentials --all. La CLI exporte aussi les credentials (chiffrées), ce que l'API ne fait pas. Combinée avec un cron system-level et un script shell qui commit vers Git, cette approche fonctionne même quand l'interface n8n est down.
Backup de la base de données
En production, n8n devrait tourner sur PostgreSQL. Un pg_dump quotidien capture tout d'un bloc : workflows, credentials, exécutions, configuration. C'est le filet de sécurité ultime pour le disaster recovery — vous restaurez le dump sur une nouvelle installation et tout revient, à condition d'avoir aussi conservé la N8N_ENCRYPTION_KEY.
La bonne pratique combine au moins deux de ces approches. Git pour le versioning granulaire et la lisibilité. pg_dump pour la restoration complète. Et dans tous les cas, testez la restauration. Un backup que vous n'avez jamais restauré ne prouve rien.
Minimum viable backup pour n8n — export des workflows vers Git (quotidien), sauvegardepg_dumpde la base PostgreSQL, et laN8N_ENCRYPTION_KEYstockée séparément dans un endroit sécurisé. Sans ces trois éléments, vous ne pouvez pas reconstruire votre instance.
Les workflows sont sauvegardés, les webhooks sont verrouillés. Reste le socle sur lequel tout ça tourne.
Sécuriser l'infrastructure
Reverse proxy obligatoire
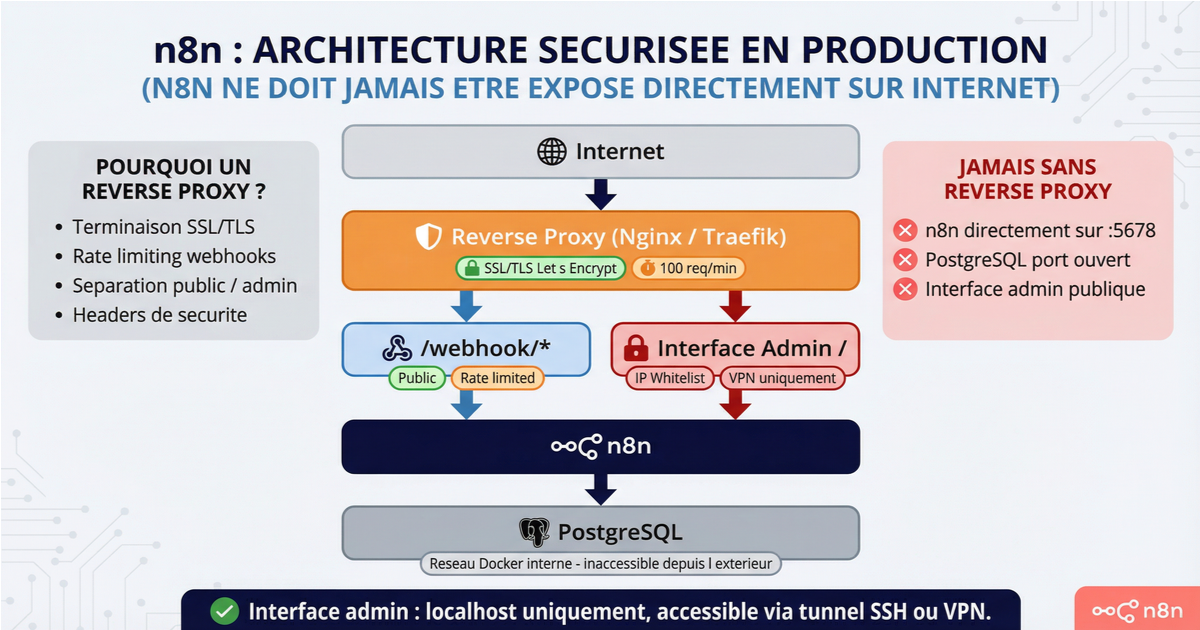
N'exposez jamais n8n directement sur internet. Jamais. L'interface d'administration, l'éditeur de workflows, et les endpoints webhook ne doivent pas être accessibles sans une couche intermédiaire.
L'architecture cible ressemble à ça :
Internet
│
▼
Reverse Proxy (Nginx / Traefik)
│
├── /webhook/* → public (rate limited)
└── / → admin (IP whitelist / VPN)
│
▼
n8n
│
▼
PostgreSQL (réseau interne Docker)
Nginx ou Traefik en reverse proxy remplit plusieurs fonctions : terminaison SSL/TLS via Let's Encrypt, rate limiting sur les endpoints webhook, séparation des chemins entre les webhooks publics et l'interface admin restreinte, et headers de sécurité standards.
Les WebSocket upgrade headers sont indispensables pour que l'interface n8n fonctionne correctement derrière un reverse proxy. Sans eux, l'éditeur mouline indéfiniment. C'est le problème le plus fréquent remonté sur le forum communautaire.
Pour les environnements qui demandent un niveau de sécurité supplémentaire, l'interface admin peut être bindée uniquement sur localhost et exposée via un tunnel SSH ou un VPN. Les webhooks restent accessibles publiquement via le reverse proxy, mais l'éditeur n'est jamais directement atteignable depuis l'extérieur.
PostgreSQL et la clé de chiffrement
SQLite est le défaut de n8n. Ça fonctionne pour du développement et des petits volumes. En production, les limites apparaissent rapidement : verrouillage en écriture concurrente, performance dégradée quand l'historique d'exécutions grandit, impossibilité de faire des backups à chaud sans risque de corruption. PostgreSQL résout ces problèmes. Partez directement dessus — la migration après coup est pénible. Et gardez la base sur un réseau interne Docker, inaccessible depuis l'extérieur.
L'autre élément critique de votre infrastructure, c'est la variable N8N_ENCRYPTION_KEY. Elle chiffre toutes les credentials stockées — clés API, tokens OAuth, mots de passe de bases de données. Sur une instance avec 30 intégrations, perdre cette clé représente des heures de reconfiguration manuelle. Générez une chaîne aléatoire d'au moins 32 caractères et stockez-la séparément de votre backup de base de données. Si quelqu'un accède au dump PostgreSQL et à la clé de chiffrement, il a accès à toutes vos credentials en clair. Un gestionnaire de secrets dédié (HashiCorp Vault, AWS Secrets Manager) est idéal. Un fichier chiffré dans un endroit séparé de vos backups est le minimum.
Mettre à jour sans casser
Avec Docker, la mise à jour est techniquement simple : pull la nouvelle image, recréer le container. Vos données survivent dans le volume persistant.
Ce qui manque souvent dans la pratique : lire le changelog avant. Les major versions de n8n introduisent régulièrement des breaking changes — nodes renommés, comportements modifiés, API dépréciées. Sur des workflows critiques, testez d'abord sur une instance séparée. Et vérifiez que votre backup le plus récent est fonctionnel avant de lancer la mise à jour. La fenêtre entre "j'ai cassé mon instance" et "je peux restaurer" ne devrait jamais dépendre d'un backup vieux de trois jours.
Les erreurs qui coûtent cher
La plus fréquente : l'URL du webhook qui fuit. Partagée dans du code front-end, copiée dans une documentation publique, commitée dans un repo GitHub ouvert. Traitez vos URLs de webhook comme des credentials. Elles n'ont rien à faire en clair dans un endroit accessible.
Vient ensuite la fuite d'information par les messages d'erreur. Quand un webhook retourne une erreur, le message par défaut de n8n peut révéler des détails sur votre infrastructure — noms de nodes, chemins de fichiers, versions de services. Un node "Respond to Webhook" avec un message générique pour l'extérieur, et le détail loggé en interne, règle le problème.
Sur la N8N_ENCRYPTION_KEY, je me répète volontairement parce que c'est l'erreur la plus coûteuse. Le jour où votre instance meurt sans cette clé sauvegardée, chaque intégration est à recréer de zéro.
Et le grand classique : le backup jamais testé. Un fichier JSON sur Google Drive ne garantit rien tant que vous n'avez pas vérifié qu'il se réimporte correctement sur une instance vierge.
Checklist sécurité et maintenance
Avant de considérer votre instance n8n comme "en production" :
Chaque webhook a une authentification activée (header auth au minimum, HMAC pour les paiements). n8n tourne derrière un reverse proxy avec SSL/TLS. L'interface admin est restreinte par IP ou VPN. La base de données est PostgreSQL, accessible uniquement depuis le réseau Docker interne. La N8N_ENCRYPTION_KEY est générée, stockée séparément, et documentée. Un backup automatique quotidien est en place (Git ou cloud storage) et un pg_dump séparé pour la base. La restauration a été testée au moins une fois sur une instance vierge. Le rate limiting est configuré au niveau du reverse proxy. Un Error Workflow centralisé est en place pour les alertes (cf. article précédent de la série).
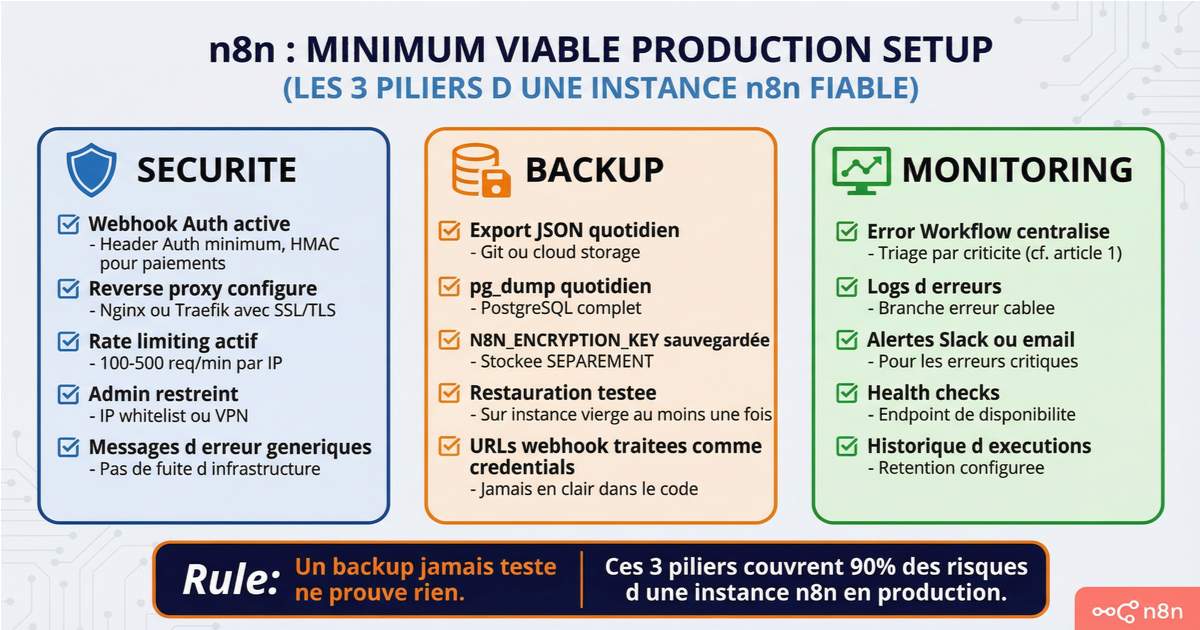
Ces neuf points couvrent 90% des risques d'une instance n8n en production. Le reste dépend de votre contexte spécifique — compliance RGPD, nombre d'utilisateurs, criticité des workflows.
Pour la suite
Le troisième et dernier volet de cette série couvrira l'architecture de déploiement avancée : queue mode pour le scaling horizontal, séparation des workers, CI/CD pour les workflows, et comment structurer une instance n8n quand elle passe de "l'outil d'un freelance" à "l'infrastructure d'une équipe".
Sources et crédits : la vidéo de Vince (Krea City) et Abdel sur la sécurisation de n8n a inspiré la structuration de cet article trop longtemps rester dans mes drafts.