n8n en production : de l'outil personnel à la plateforme d'équipe

Troisième et dernier volet de la série "n8n en production : le guide complet"
Les deux premiers articles couvraient l'error handling et la sécurité/maintenance, ce qu'il faut pour qu'un workflow individuel tourne de façon fiable. Celui-ci s'attaque à un problème différent : que se passe-t-il quand n8n passe de l'outil d'une personne à l'infrastructure d'une équipe ?
Un freelance avec 10 workflows sur un VPS à 5 euros par mois n'a pas les mêmes contraintes qu'une équipe de 5 personnes qui fait tourner 80 workflows critiques pour des clients. La question du scaling dans n8n ne se résume pas à "ajouter de la RAM". Elle touche l'architecture d'exécution, l'organisation des workflows, la gestion des accès, et le coût réel de chaque option de déploiement.
Le queue mode : pourquoi il existe vraiment
En mode standard, n8n fait tout dans un seul process Node.js : l'interface d'édition, la réception des webhooks, et l'exécution des workflows. Le problème principal n'est pas le CPU. C'est que tous les workflows partagent le même event loop. Certains nodes bloquent (appels API synchrones, traitements lourds), et quand ça arrive, c'est l'ensemble de l'instance qui ralentit (l'éditeur compris). Un seul workflow gourmand peut figer l'interface pour tous les utilisateurs.
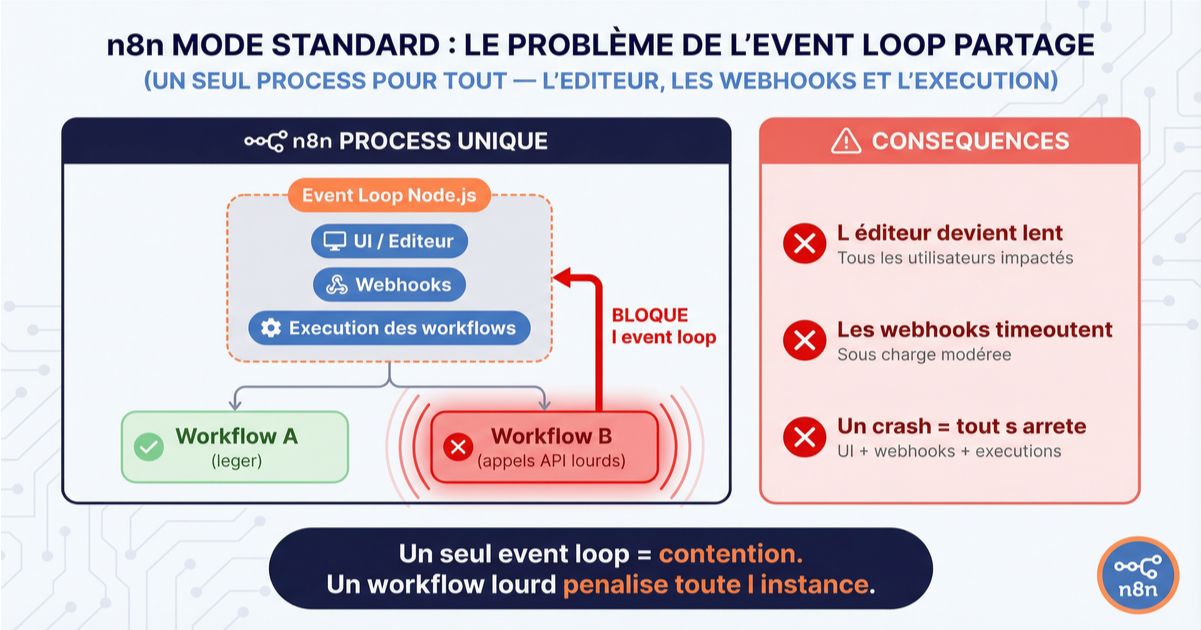
Le queue mode résout d'abord un problème d'isolation. Chaque worker possède son propre event loop, sa propre mémoire, son propre "crash domain". Un workflow qui consomme 2 Go de RAM ou qui boucle indéfiniment impacte uniquement le worker qui l'exécute. Les autres workers et le process principal continuent de tourner normalement. Le scaling horizontal, ajouter des workers pour traiter plus de jobs en parallèle, est une conséquence de cette architecture, pas sa raison d'être.
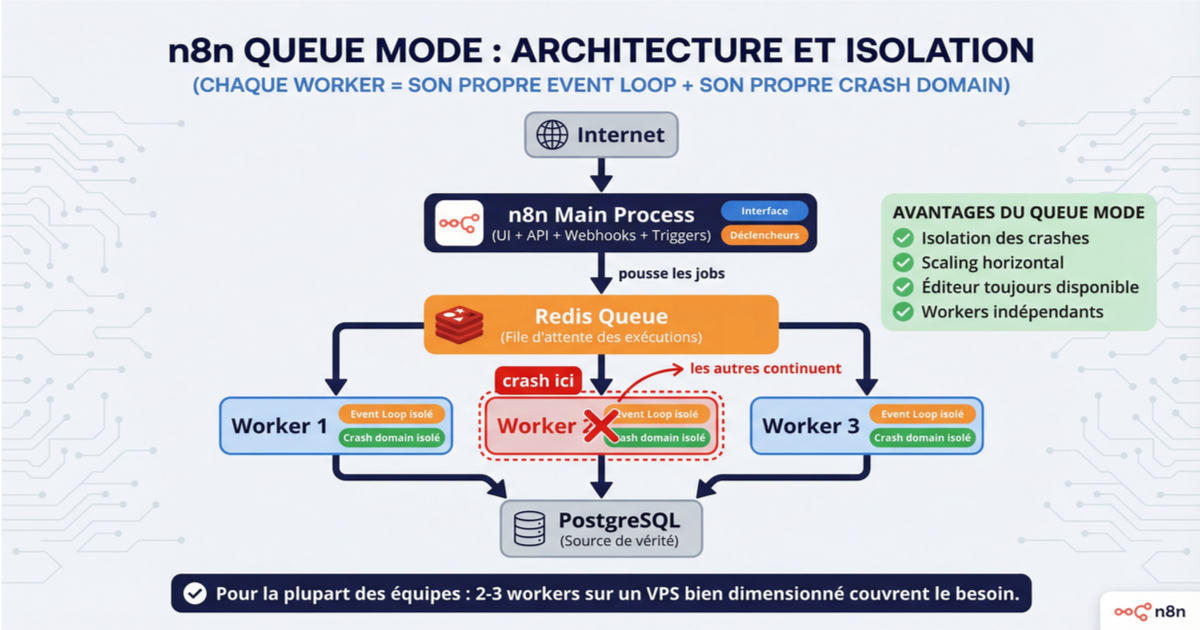
L'architecture repose sur trois composants. Le process principal gère l'interface, l'API et les déclencheurs. Il pousse les exécutions dans une queue Redis. Des workers récupèrent les jobs et les traitent. PostgreSQL reste la source de vérité.
Process principal (UI + API + triggers)
│
▼
Redis (queue des jobs)
│
┌───┴───┐
▼ ▼
Worker 1 Worker 2 ... Worker N
│ │ │
└───────┴──────────────┘
│
▼
PostgreSQL
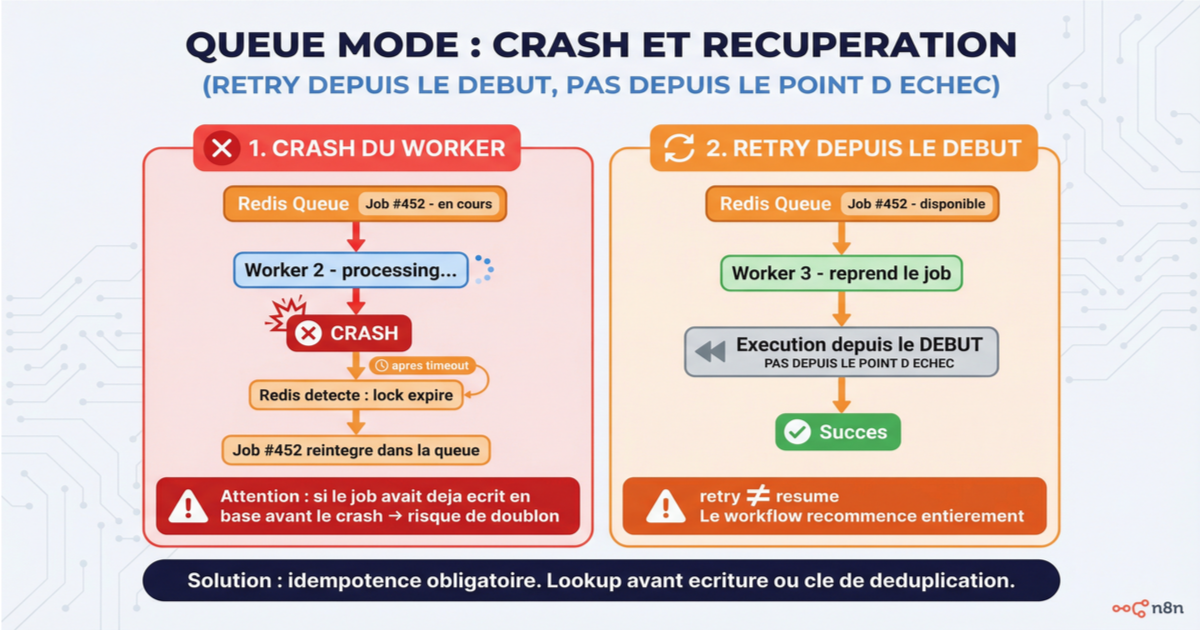
Quand un worker crashe, le mécanisme de récupération repose sur un job lock dans Redis. Le lock expire après un timeout, le job revient dans la queue, et un autre worker peut le récupérer. C'est robuste, mais avec une nuance : le job ré-exécuté reprend depuis le début, pas depuis le point d'échec. Si le workflow avait déjà envoyé des emails ou créé des enregistrements avant le crash, le retry peut produire des doublons. Le problème d'idempotence couvert dans le premier article de cette série s'applique ici aussi, et plus fortement encore.
Le coût : un minimum de trois containers au lieu de deux (main + Redis + au moins un worker, plus PostgreSQL). Pour un VPS basique, 2 à 3 workers est un bon point de départ. Chaque worker consomme du CPU et de la RAM proportionnellement à la complexité des workflows qu'il exécute.
Un détail souvent mal compris : en queue mode, les données binaires (fichiers, images) ne doivent pas être partagées via un filesystem entre le process principal et les workers. Le stockage local ne fonctionne pas dans une architecture distribuée. Pour les workflows qui manipulent des fichiers, un stockage externe type S3 ou MinIO est nécessaire.
Pour ceux qui n'ont pas besoin de scaling horizontal mais veulent quand même isoler l'exécution de l'édition, il existe une option intermédiaire : lancer le process principal et un worker sur la même machine via Docker Compose. Vous bénéficiez de la séparation des event loops sans la complexité d'une infrastructure distribuée.
Quand passer en queue mode ? Dès que vous observez un des signes suivants : l'éditeur devient lent pendant que des workflows tournent, des webhooks commencent à timeout sous la charge, ou vous avez besoin qu'un crash d'exécution n'impacte pas le reste de l'instance. Pour la plupart des équipes, 2-3 workers sur un VPS correctement dimensionné couvrent le besoin.
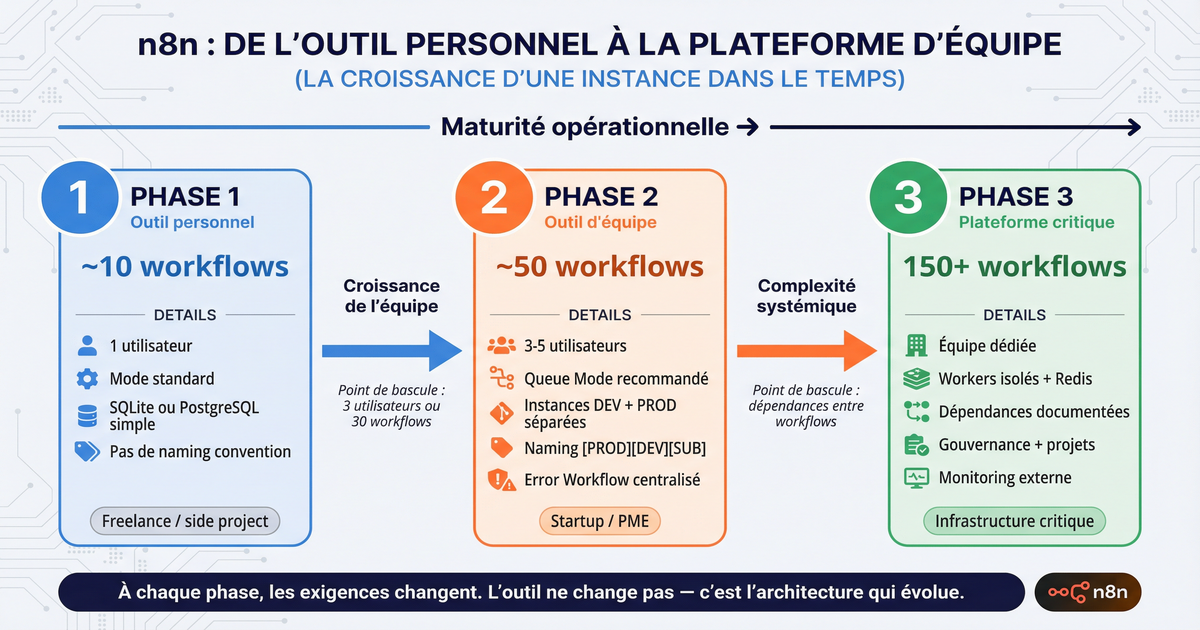
Organiser les workflows à l'échelle
Avec 10 workflows, vous vous y retrouvez. Avec 80, sans organisation, c'est le chaos. Trouver le bon workflow prend du temps, comprendre ce qu'il fait encore plus, et identifier qui l'a modifié en dernier relève de l'enquête.
Conventions de nommage
Le nommage est votre première ligne de défense. Une convention qui a fait ses preuves :
[ENV] Département - Fonction - Détail
En pratique : [PROD] Sales - Lead scoring - HubSpot to Airtable, [DEV] Finance - Factures - Génération PDF, [SUB] Notif - Slack alerting. L'environnement en premier pour le tri visuel immédiat. Le département pour savoir qui est concerné. La fonction pour comprendre ce que ça fait sans l'ouvrir.
Tags et projets
Les tags dans n8n permettent de catégoriser les workflows sur plusieurs axes : environnement (prod, dev, test), criticité (high, medium, low), département, statut (active, deprecated, draft). Un workflow peut porter plusieurs tags. C'est le seul mécanisme de filtrage efficace quand votre liste de workflows dépasse les 30 entrées.
Les projets (disponibles sur les plans Pro et Enterprise) ajoutent une couche de structure : ils regroupent workflows et credentials dans des espaces isolés, avec des permissions par équipe. Si vous avez plusieurs départements qui utilisent n8n, les projets évitent que l'équipe marketing modifie accidentellement un workflow de facturation.
Le vrai problème à l'échelle : les dépendances implicites
Le nommage et les tags résolvent la navigation. Ils ne résolvent pas le problème le plus sournois qui émerge au-delà de 50 workflows : les dépendances implicites entre workflows.
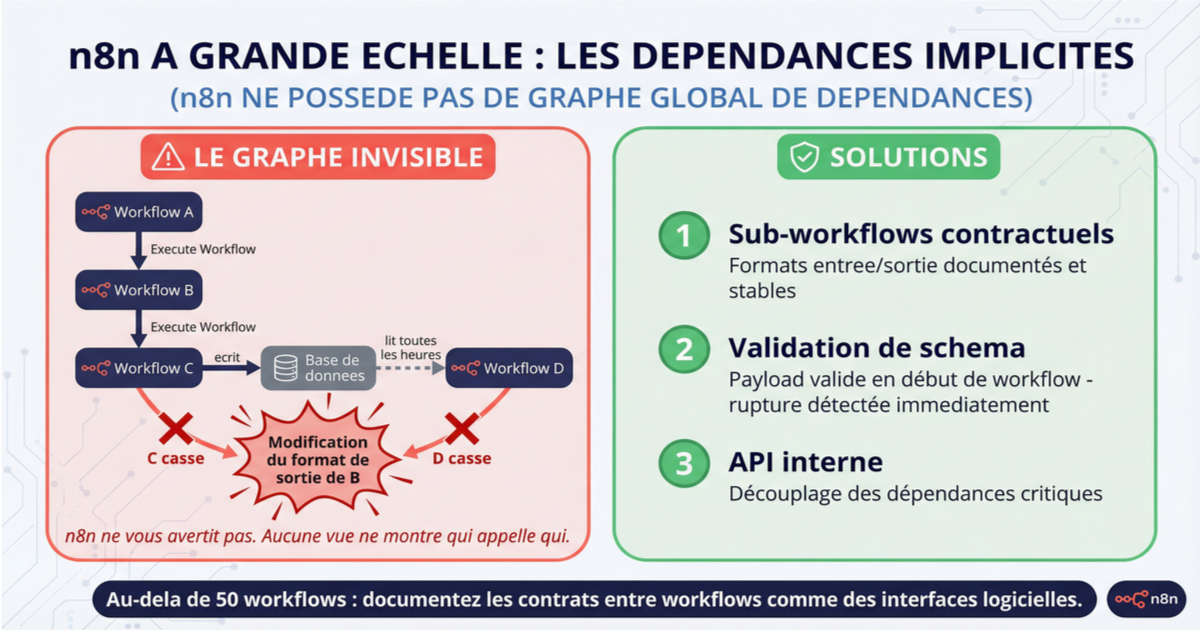
En pratique, ça ressemble à ça : le workflow A appelle le workflow B via Execute Workflow, le workflow B appelle le workflow C, le workflow C écrit dans une base de données que le workflow D lit toutes les heures. Modifier le format de sortie de B casse C et D en cascade. n8n ne possède pas de graphe global de dépendances — aucune vue ne vous montre qui appelle qui et quel impact une modification peut avoir en aval.
Les équipes qui passent le cap des 100 workflows finissent par créer leurs propres gardes-fous. Des sub-workflows "contractuels" avec des formats d'entrée/sortie documentés et stables. Des schemas de payload validés en début de workflow pour détecter les ruptures de contrat immédiatement. Parfois une API interne entre les workflows critiques pour découpler les dépendances. C'est de l'ingénierie logicielle appliquée au no-code, et c'est exactement ce qui arrive quand l'automatisation atteint une certaine densité.
Environnements et déploiement
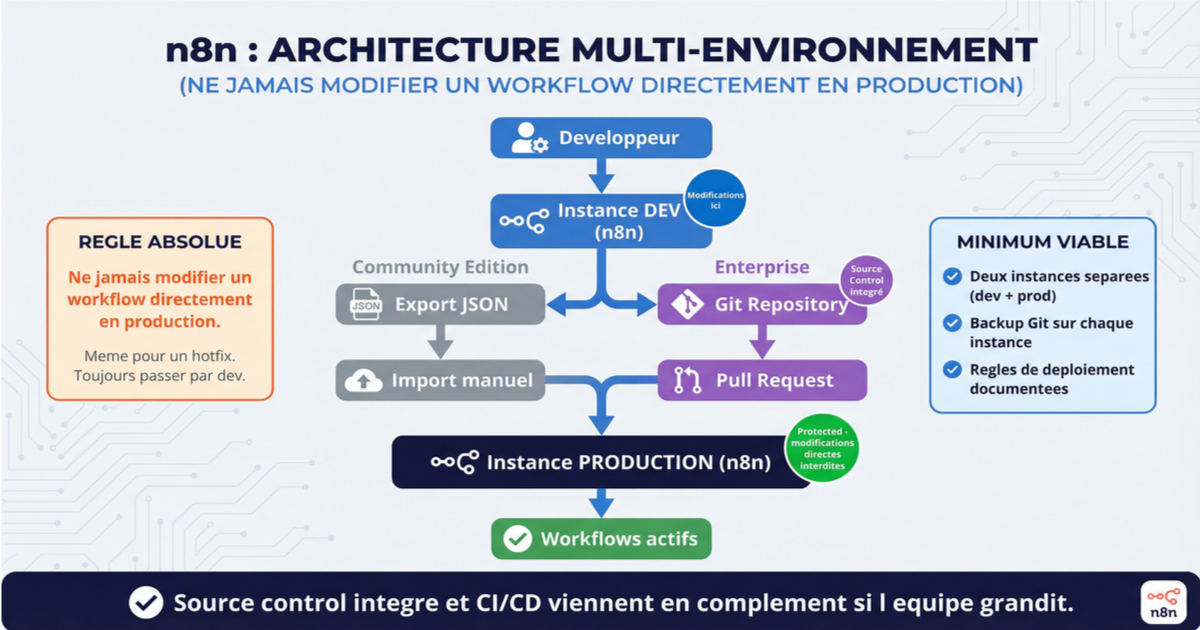
Dev, staging, prod : le modèle à deux instances minimum
En développement logiciel, personne ne modifie du code directement en production. L'automatisation devrait suivre la même discipline. Modifier un workflow actif qui traite des données clients pour tester une idée, c'est prendre un risque inutile.
n8n Enterprise propose un source control intégré basé sur Git. Chaque instance est liée à une branche Git. Vous développez sur l'instance dev, vous poussez vers la branche dev, vous créez une pull request vers la branche prod, et vous tirez les changements sur l'instance de production. L'instance prod peut être marquée comme "Protected" pour empêcher toute modification directe.
En Community Edition, le source control n'existe pas nativement. L'alternative : deux instances séparées (dev et prod), avec un backup Git automatisé sur chaque instance (cf. article 2 de cette série). Le déploiement vers la prod se fait par export JSON depuis dev et import sur prod. C'est manuel, mais ça pose déjà une discipline de séparation.
Un point que la documentation ne mentionne pas : n8n ne synchronise pas les credentials ni les valeurs de variables entre instances. Quand vous tirez un workflow de dev vers prod, les credentials doivent être configurées manuellement sur chaque instance. C'est voulu — vos credentials de dev et de prod ne devraient pas être les mêmes — mais ça surprend au premier déploiement.
CI/CD pour les workflows
Pour les équipes qui veulent aller plus loin, le déploiement peut être automatisé. Un GitHub Action qui détecte un merge sur la branche prod, appelle l'API n8n de l'instance de production pour tirer les changements, et notifie l'équipe sur Slack. Le pipeline ressemble à du déploiement logiciel classique, adapté au contexte no-code.
La validation avant déploiement est le maillon faible. Il n'existe pas de framework de test natif pour les workflows n8n. Vous ne pouvez pas écrire de tests unitaires sur un workflow. La validation se fait par exécution manuelle sur l'instance de dev, relecture par un pair, et vérification post-déploiement en prod. C'est artisanal, mais c'est l'état de l'art actuel.
Minimum viable pour le déploiement — deux instances séparées (dev et prod), un backup Git sur chaque, et la règle absolue de ne jamais modifier un workflow directement en production. Le source control intégré et le CI/CD viennent en complément si l'équipe grandit.
Gestion des accès
RBAC : qui peut faire quoi
Le contrôle d'accès basé sur les rôles est disponible sur les plans Pro et Enterprise. En Community Edition, tous les utilisateurs ont les mêmes droits, ce qui pose un problème évident quand 5 personnes partagent la même instance.
Le RBAC de n8n fonctionne par projets. Vous créez un projet, vous y assignez des workflows et des credentials, et vous définissez des rôles pour chaque utilisateur dans ce projet. Un même utilisateur peut être admin sur le projet Marketing et viewer sur le projet Finance. Les rôles déterminent qui peut créer, modifier, exécuter ou simplement consulter les workflows.
Pour les organisations régulées (banque, santé, assurance), l'audit trail est un complément indispensable. Chaque modification de workflow, chaque exécution, chaque changement de permission est tracé. C'est une exigence pour les certifications ISO 27001, SOC 2 ou la conformité RGPD. Le log streaming vers un SIEM externe (couvert dans l'article 1) alimente ce besoin.
SSO et authentification centralisée
n8n Enterprise s'intègre avec les fournisseurs d'identité via SAML et LDAP — Okta, Azure AD, Google Workspace. Ça évite de gérer un système de comptes séparé et permet d'appliquer les politiques de sécurité existantes de l'organisation (MFA, rotation de mots de passe, révocation centralisée).
En Community Edition, la gestion des utilisateurs est basique : des comptes locaux avec email et mot de passe. Si votre équipe dépasse 5 personnes et que la sécurité des accès est un sujet, c'est souvent le premier argument qui justifie le passage à un plan payant.
Le vrai coût de chaque option
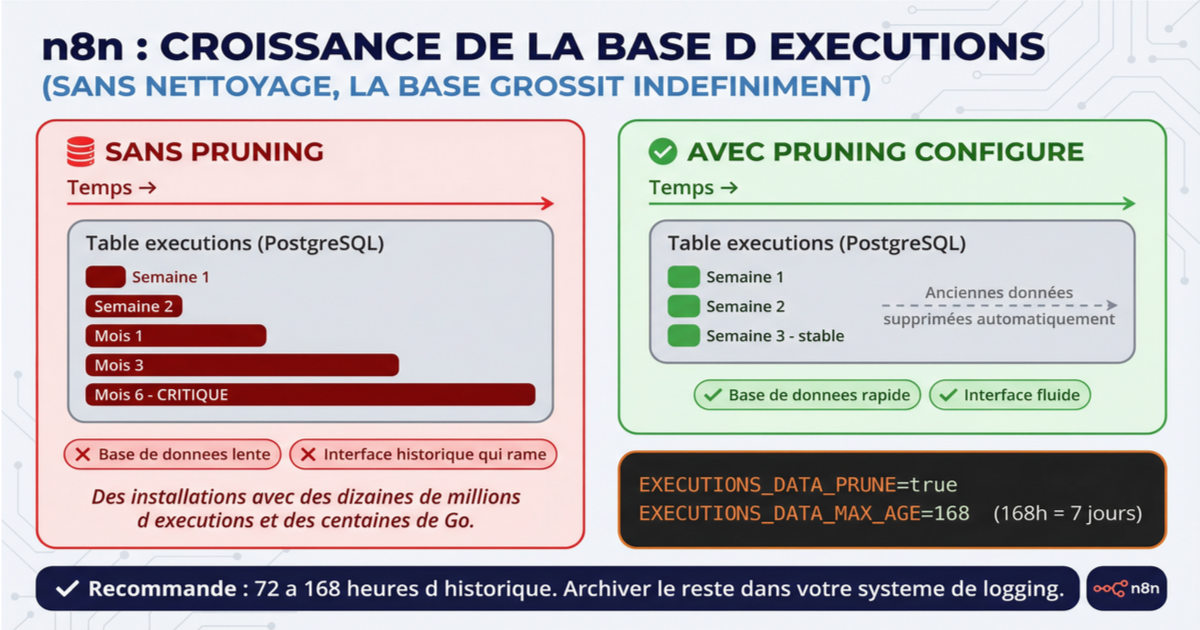
Avant de parler pricing, un point d'hygiène que beaucoup d'installations négligent : le pruning des exécutions. Par défaut, n8n stocke les données de chaque exécution dans PostgreSQL — les entrées, les sorties, les logs, les binaires, les métadonnées. Sans configuration de nettoyage, la base grossit indéfiniment. On voit des installations avec des dizaines de millions d'exécutions et des centaines de Go de données. Le problème n'est pas seulement le disque : les requêtes deviennent lentes, l'interface d'historique rame, et certaines migrations de version peuvent devenir risquées sur des tables aussi volumineuses.
Deux variables d'environnement règlent le problème : EXECUTIONS_DATA_PRUNE=true et EXECUTIONS_DATA_MAX_AGE (en heures). Sur la plupart des installations, conserver 72 à 168 heures d'historique suffit pour le debugging. Le reste devrait être archivé dans votre système de logging externe si vous en avez besoin pour l'audit.
Le choix entre Community self-hosted, Cloud, et Enterprise dépend moins du prix affiché que du coût total — infrastructure, maintenance, temps humain.
La Community Edition self-hosted est gratuite côté licence. Le coût réel commence à 50-80 euros par mois pour un VPS avec PostgreSQL, reverse proxy, et backups. En queue mode avec plusieurs workers, comptez 100-200 euros d'infrastructure. Ajoutez 10 à 20 heures de DevOps par mois pour la maintenance, les mises à jour, et le debugging. Pour une équipe sans compétence infrastructure, ce coût caché peut dépasser largement le prix d'un plan Cloud.
n8n Cloud démarre à 24 euros par mois pour 2 500 exécutions. Le plan Pro à 60 euros offre 10 000 exécutions. La facturation par exécution signifie que les coûts sont prévisibles tant que votre volume est stable, mais ils peuvent exploser si vos workflows se déclenchent fréquemment. Un workflow webhook qui se déclenche 100 fois par jour sur 50 workflows, c'est 150 000 exécutions par mois — bien au-delà du plan Pro.
L'Enterprise (Cloud ou self-hosted) ajoute RBAC, SSO, audit trail, source control, log streaming, et support dédié. Le pricing est custom et commence généralement à plusieurs centaines d'euros par mois. C'est l'option quand la governance et la compliance ne sont pas optionnelles.
Repère décisionnel — si votre équipe peut gérer l'infrastructure, que vos volumes sont élevés, et que vous n'avez pas besoin de SSO/RBAC, le self-hosted Community est imbattable en coût. Si personne dans l'équipe ne veut toucher à Docker, le Cloud est le bon choix. Si la compliance est un sujet, l'Enterprise s'impose quelle que soit votre préférence.
Ce que cette série couvre au final
En trois articles, on a parcouru les trois couches qui séparent un n8n de démonstration d'un n8n de production. L'error handling pour que les workflows gèrent les échecs au lieu de les subir. La sécurité et la maintenance pour que l'instance soit protégée et récupérable. L'architecture pour que le tout tienne à l'échelle d'une équipe.
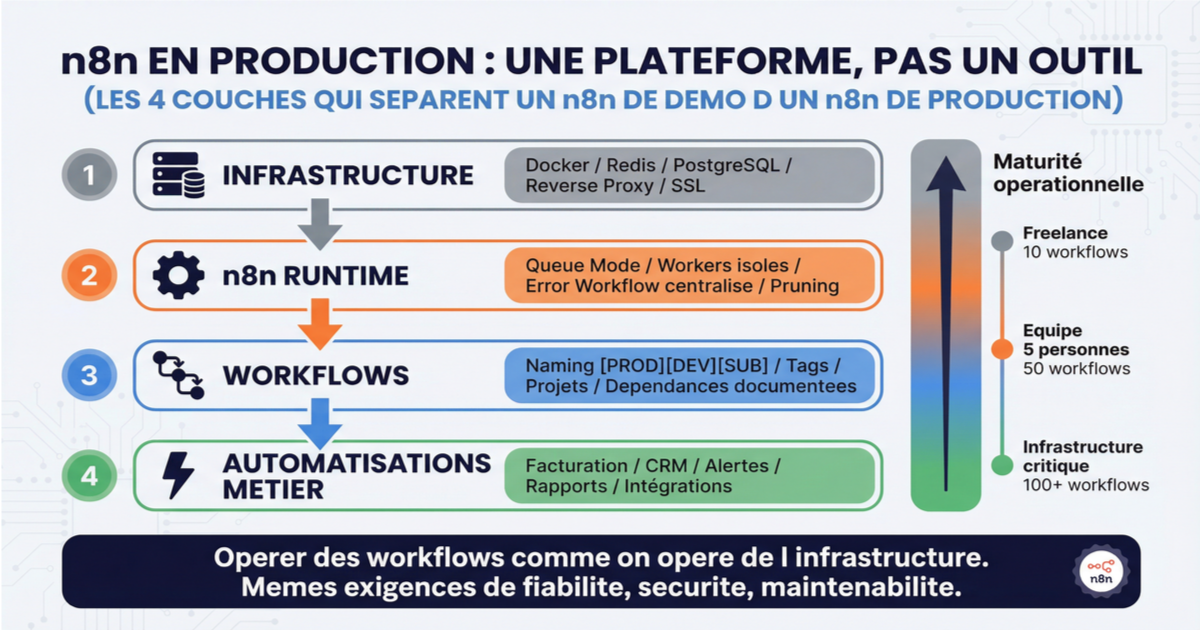
La plupart des tutoriels n8n s'arrêtent à "voici comment connecter Slack à Google Sheets". Ce qui rend n8n intéressant en contexte professionnel, c'est justement ce qui vient après : opérer des workflows comme on opère de l'infrastructure. Avec les mêmes exigences de fiabilité, de sécurité, et de maintenabilité.
Sources : documentation officielle n8n (queue mode, source control, RBAC, pricing).