Error handling dans n8n : le guide.

La plupart des contenus sur la gestion d'erreurs dans n8n s'arrêtent au même endroit : activez "Retry on Fail", créez un Error Workflow, envoyez une notif Slack. Sauf qu'en production, vos erreurs arrivent à 3h du matin, sur un edge case que vous n'aviez pas envisagé, dans un workflow qui traite 500 items dont 498 auraient pu passer sans problème. Et le "Retry on Fail" ne vous sauvera pas d'une API qui renvoie un 200 avec un body vide.
Cet article couvre ce que j'applique sur mes propres workflows en production — les patterns, les architectures, et les limites réelles de ce que n8n propose nativement.
Les quatre mécanismes natifs et leurs angles morts
Avant de les détailler, un point fondamental sur le fonctionnement du moteur n8n. Les erreurs dans n8n sont item-based, pas workflow-based. Un node reçoit un tableau d'items, les traite un par un, et chaque item peut échouer indépendamment. Sur 500 items, un seul peut planter pendant que les 499 autres passent. Toute la logique d'error handling de n8n découle de ce design. Gardez ça en tête, ça éclaire le comportement de chaque mécanisme qui suit.
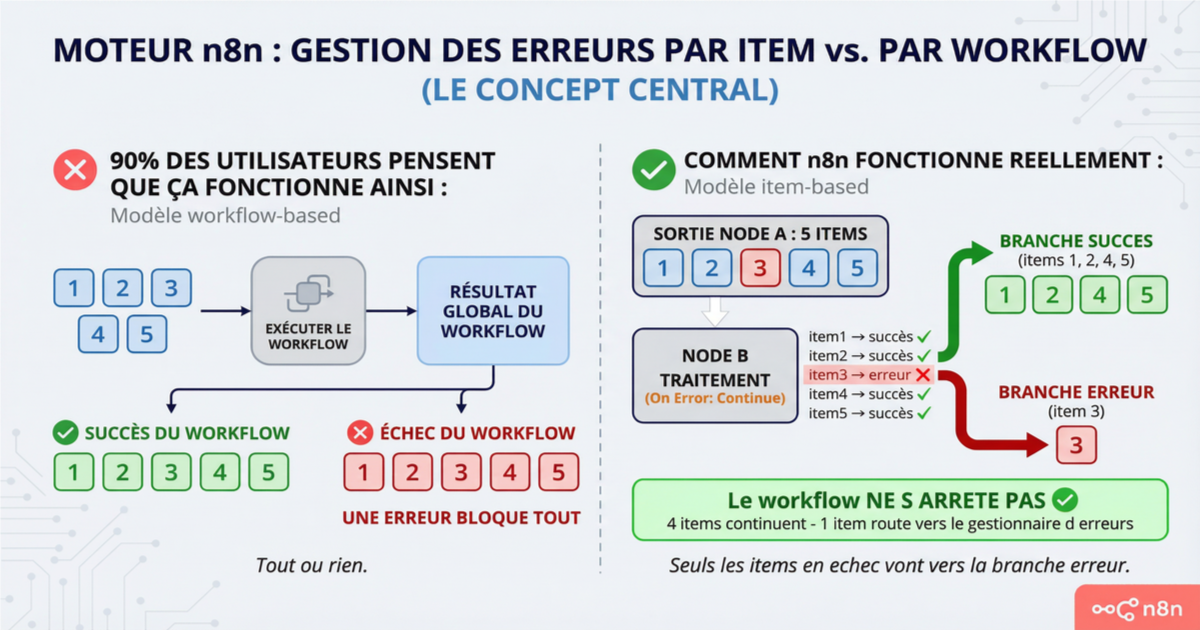
Le paramètre "On Error" existe sur chaque node et offre trois options : stopper le workflow, continuer en passant l'erreur dans le flux normal, ou continuer en routant vers une sortie dédiée aux erreurs. La troisième option — "Continue (using error output)" — est la plus utile en production parce qu'elle permet de traiter les erreurs sans contaminer le flux principal. En pratique, elle a un problème connu : si vous combinez "Retry on Fail" avec "Continue (using error output)", le retry ne fonctionne pas comme attendu. Le node retourne une erreur dès le premier échec, sans attendre les tentatives de retry. C'est documenté dans les issues GitHub de n8n, pas dans la documentation officielle.
"Retry on Fail" est le deuxième mécanisme. Vous configurez un nombre de tentatives et un délai entre chaque essai. Ça fonctionne bien pour les erreurs transitoires — une API momentanément indisponible, un timeout réseau. Pour les appels API externes, 3 à 5 retries avec 5 secondes d'intervalle est un bon défaut. Mais le retry ne fait que répéter exactement la même requête. Si l'erreur vient d'une donnée malformée, vous allez juste échouer 5 fois au lieu d'une.

Une limite plus vicieuse : le retry opère au niveau du node, pas de l'item. Si votre node reçoit 100 items et que l'item 47 échoue, le retry va reprocesser les 100 items — y compris les 46 qui avaient déjà réussi. Sur un node qui écrit en base de données ou crée des enregistrements, ça peut générer des doublons. Peu de gens réalisent ce comportement avant de le rencontrer en production.
L'Error Trigger est le troisième mécanisme. Vous créez un workflow dédié qui se déclenche quand un autre workflow échoue. C'est le filet de sécurité global. Il reçoit l'ID d'exécution, l'URL pour rejouer, le message d'erreur, le nom du workflow et du node fautif. Trois choses à savoir : l'Error Trigger ne se déclenche pas sur les exécutions manuelles (uniquement en mode automatique). Si l'erreur survient dans le trigger node lui-même, les données reçues sont différentes et contiennent moins d'informations. Et surtout — c'est une source de confusion fréquente — l'Error Trigger ne capte que les erreurs non interceptées. Un node configuré en "Continue on Error" ne déclenchera jamais l'Error Workflow, puisque l'erreur est considérée comme gérée. Si vous mettez du "Continue on Error" partout pour éviter les crashs, vous désactivez aussi votre système d'alerte global. Il faut choisir consciemment, node par node, entre gérer l'erreur localement et la laisser remonter.
Le node "Stop and Error" est le quatrième. Il permet de forcer un échec avec un message personnalisé. C'est l'équivalent d'un throw en code. Utile pour valider des hypothèses sur les données entrantes et déclencher l'Error Workflow avec un message explicite plutôt qu'un cryptique "Cannot read property X of undefined".
Les patterns qui tiennent en production
Isoler les opérations risquées
Tout ce qui implique un appel externe — API tierce, base de données, service d'envoi d'emails — devrait vivre dans un sub-workflow appelé via le node "Execute Workflow". La raison est simple : si le sub-workflow échoue, le workflow parent peut intercepter l'erreur et décider quoi faire, sans que le reste de l'exécution soit impacté.
Concrètement, vous avez un workflow principal qui orchestre la logique métier, et des sub-workflows spécialisés pour chaque interaction externe. Le sub-workflow qui appelle HubSpot, celui qui écrit dans Google Sheets, celui qui envoie le Slack. Si HubSpot est lent, votre Google Sheets continue de se remplir.
Ce pattern a un coût : la complexité de navigation. Avec 15 sub-workflows, retrouver où se situe un bug demande de la discipline dans le nommage. J'utilise un préfixe systématique : [SUB] CRM - Création lead, [SUB] Notif - Slack alerting. Et pour les workflows principaux en production, le préfixe [PROD].
Le try/catch local
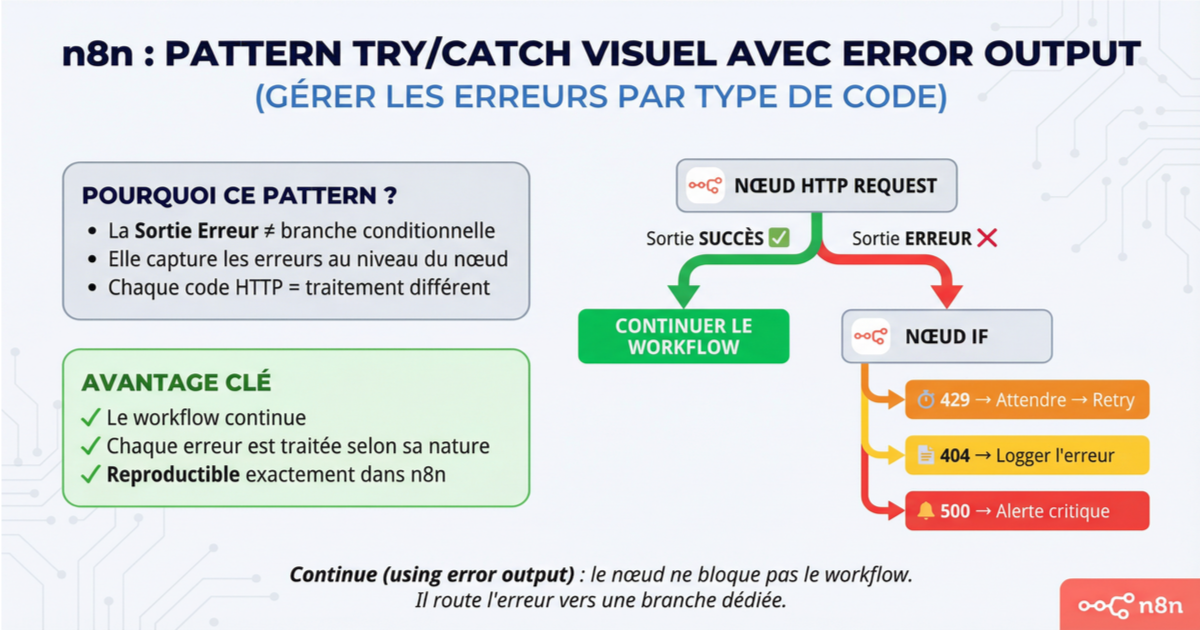
Pour les cas où un sub-workflow serait excessif, le pattern try/catch local fonctionne. Sur le node risqué, activez "Continue (using error output)". Ça crée une deuxième sortie sur le node. Branchez la sortie normale vers la suite du workflow, et la sortie erreur vers votre logique de récupération.
Dans la branche erreur, l'item contient une propriété error avec le message et les détails. Vous pouvez utiliser un node IF ou Switch pour décider : est-ce une erreur 429 (rate limit) qu'on peut retenter après un délai ? Un 404 (ressource introuvable) qu'on doit logger et ignorer ? Un 500 qui justifie une alerte immédiate ?
Le piège classique : quand vous activez "Continue (using error output)", les deux branches s'exécutent en parallèle. Si votre branche erreur envoie une réponse webhook et que votre branche succès fait de même, vous aurez un conflit. Pensez à terminer la branche erreur proprement, par exemple avec un node "Stop and Error" si vous voulez quand même déclencher l'Error Workflow global, ou un Respond to Webhook avec le bon code HTTP.
Rendre le batch processing résilient
Le scénario classique : vous traitez 500 leads d'un import CSV. Le lead 47 a un email malformé. Sans error handling, les leads 48 à 500 ne seront jamais traités.
La solution combine "Split In Batches" avec "Continue on Fail". Découpez vos items en lots (10 à 50 selon le volume), activez "Continue (using error output)" sur les nodes de traitement, et dans la branche erreur, collectez les items échoués dans un tableur ou une base de données pour retraitement ultérieur.
Une clarification importante : "Split In Batches" est un mécanisme de contrôle de flux, pas de gestion d'erreur. Il découpe vos données en lots pour éviter les timeouts et respecter les rate limits. C'est "Continue on Error" qui rend le traitement résilient. Les deux ensemble font le travail, mais c'est facile de confondre leurs rôles.
L'erreur que je vois régulièrement : collecter les erreurs mais ne jamais les retraiter. Un tableur Google Sheets "Erreurs à traiter" qui grossit indéfiniment. Si vous collectez des erreurs, créez aussi le workflow de retraitement. Sinon, vous avez juste déplacé le problème.
Les pièges silencieux : idempotence et concurrence
L'error handling ne se limite pas à intercepter les échecs. Deux problèmes reviennent systématiquement en production et n'ont rien à voir avec des nodes qui plantent.
Le premier, c'est l'idempotence. Quand un retry se déclenche sur un node qui crée une facture, vous risquez de créer deux factures. Quand un webhook est appelé deux fois suite à un timeout côté émetteur, vous risquez de traiter la même commande deux fois. Le retry résout le problème de la disponibilité mais introduit le problème du doublon. Les workflows robustes intègrent une vérification avant écriture — un lookup pour vérifier que l'enregistrement n'existe pas déjà, ou une clé de déduplication qui empêche les insertions en double. Sans ça, votre error handling "qui marche" peut générer des incohérences de données que personne ne détecte pendant des semaines.
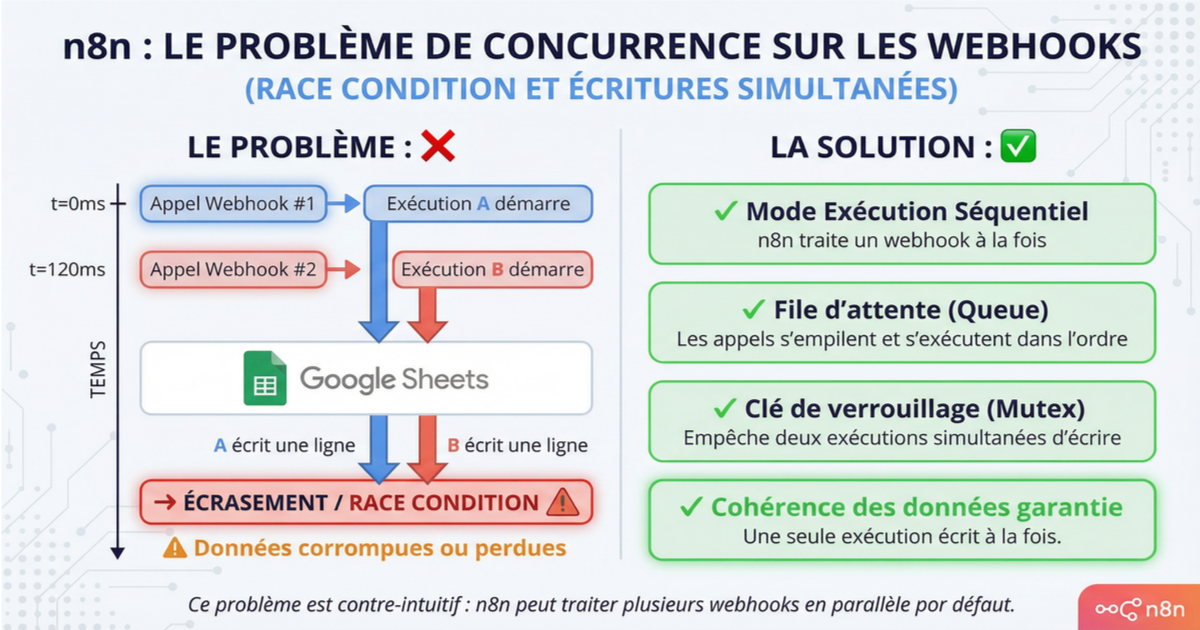
Le second, c'est la concurrence sur les webhooks. Rien n'empêche deux exécutions du même workflow de tourner en parallèle. Un webhook appelé deux fois en 200ms lance deux exécutions simultanées. Sur des services comme Google Sheets, Notion ou Airtable qui ne gèrent pas bien les écritures concurrentes, ça crée des conflits silencieux — lignes écrasées, données manquantes, incohérences. Les API robustes (PostgreSQL, Stripe) gèrent ça nativement. Les autres nécessitent soit un mécanisme de queue en amont, soit un verrouillage logique dans votre workflow.
Au-delà du natif : l'architecture de monitoring
Les mécanismes natifs de n8n gèrent les erreurs au niveau du workflow. En production, vous avez besoin de visibilité au niveau de l'infrastructure.
Error Workflow centralisé avec triage
Plutôt que de créer un Error Workflow par workflow de production, créez-en un seul qui centralise tout. Ce workflow reçoit les erreurs de tous vos workflows et fait du triage basé sur la criticité.
Le principe : un node Switch qui examine le nom du workflow source. Si c'est un workflow critique (traitement de paiements, génération de contrats), alerte Slack prioritaire avec mention @channel plus notification SMS ou push. Si c'est un workflow secondaire (agrégation de news, reporting hebdomadaire), log dans un tableur et notification Slack standard dans un channel dédié.
Les données disponibles dans l'Error Trigger suffisent pour ce routage : execution.workflow.name pour identifier le workflow source, execution.error.message pour le message, execution.error.node pour le node fautif, et execution.url pour le lien direct vers l'exécution échouée.
Log streaming et monitoring externe
n8n Cloud et la version Enterprise self-hosted proposent le log streaming. Il permet d'envoyer les événements d'exécution vers vos outils de monitoring existants. C'est la bonne approche si vous avez déjà un stack d'observabilité (Datadog, Grafana/Loki, ELK).
Pour les déploiements self-hosted en Community Edition, l'endpoint /metrics expose des métriques Prometheus. Vous pouvez monitorer le taux d'exécutions réussies vs échouées, les durées d'exécution, et la consommation mémoire. Combiné avec Grafana, ça donne un dashboard de santé de votre instance n8n.
Les métriques à surveiller en priorité : le ratio succès/échec par workflow (une dégradation progressive indique souvent un problème upstream), la durée d'exécution P95 (un spike signale un service externe lent ou un volume inhabituel), et la consommation mémoire du process Node.js (n8n peut devenir gourmand sur les gros volumes).
Pour ceux qui n'ont ni l'édition Enterprise ni le temps de monter un Prometheus, la solution pragmatique reste un workflow n8n dédié au health check. Un cron toutes les 5 minutes qui vérifie que les workflows critiques ont bien tourné dans la fenêtre attendue, en interrogeant l'API interne de n8n sur les dernières exécutions. Si un workflow attendu toutes les heures n'a pas tourné depuis 90 minutes, alerte.
Logging métier dans les workflows
Le logging d'infrastructure (n8n a crashé, un workflow a échoué) est nécessaire mais pas suffisant. En production, vous avez aussi besoin de logging métier : combien de leads traités, combien d'emails envoyés, combien de factures générées par exécution.
La technique : ajouter des nodes HTTP Request à des points stratégiques de vos workflows pour envoyer des événements vers votre service de logging. Si vous n'avez pas de stack logging, un Google Sheets ou un Airtable fait le travail pour les petits volumes. Pour les gros volumes, un webhook vers un endpoint Loki ou Elasticsearch.
Le coût de cette approche est réel : chaque node de logging ajoute de la latence et de la complexité visuelle au workflow. Réservez-le aux workflows critiques et aux métriques qui influencent vos décisions.
Les manques structurels
Après plusieurs mois d'utilisation intensive, quelques frustrations reviennent régulièrement.
La plus évidente : il n'existe pas de try/catch natif au sens classique du terme. Le pattern "Continue (using error output)" s'en approche, mais il faut l'activer node par node. Impossible d'encapsuler un groupe de nodes dans un bloc try/catch. La communauté le demande depuis longtemps dans les feature requests. L'alternative reste d'isoler la séquence dans un sub-workflow.
Le replay d'exécutions échouées, lui, existe mais reste basique. Rejouer une exécution depuis l'interface, c'est manuel et unitaire. Pas de replay en masse, pas de replay conditionnel pour ne retraiter que les items échoués d'un batch. Pour ça, il faut construire votre propre mécanisme — stocker les items échoués quelque part et avoir un workflow dédié qui les récupère.
Côté credentials, c'est un vrai point aveugle. Quand un token OAuth expire ou qu'une clé API est révoquée, le workflow échoue avec un message qui ne dit pas toujours clairement que c'est un problème d'authentification. Aucun mécanisme natif de rotation ou de vérification proactive. Un workflow de health check qui teste régulièrement vos connexions critiques compense partiellement.
Même constat sur la visibilité des exécutions longues. Un workflow qui tourne depuis 45 minutes alors qu'il devrait en prendre 5 ne déclenche aucune alerte nativement. C'est le type de monitoring que vous devez construire vous-même, via les métriques Prometheus ou via un workflow de surveillance dédié.
Enfin, tout ce qui précède suppose un mode d'exécution standard. En queue mode avec Redis et des workers séparés, la gestion d'erreurs change significativement — un worker qui crashe voit son job ré-attribué automatiquement. C'est un sujet à part entière qui sera couvert dans le troisième volet de cette série.
Checklist avant de passer un workflow en production
Avant d'activer un workflow et de le laisser tourner sans supervision, vérifiez ces points. Ce n'est pas une liste de bonnes pratiques théoriques — chaque point correspond à un problème réel que j'ai rencontré.

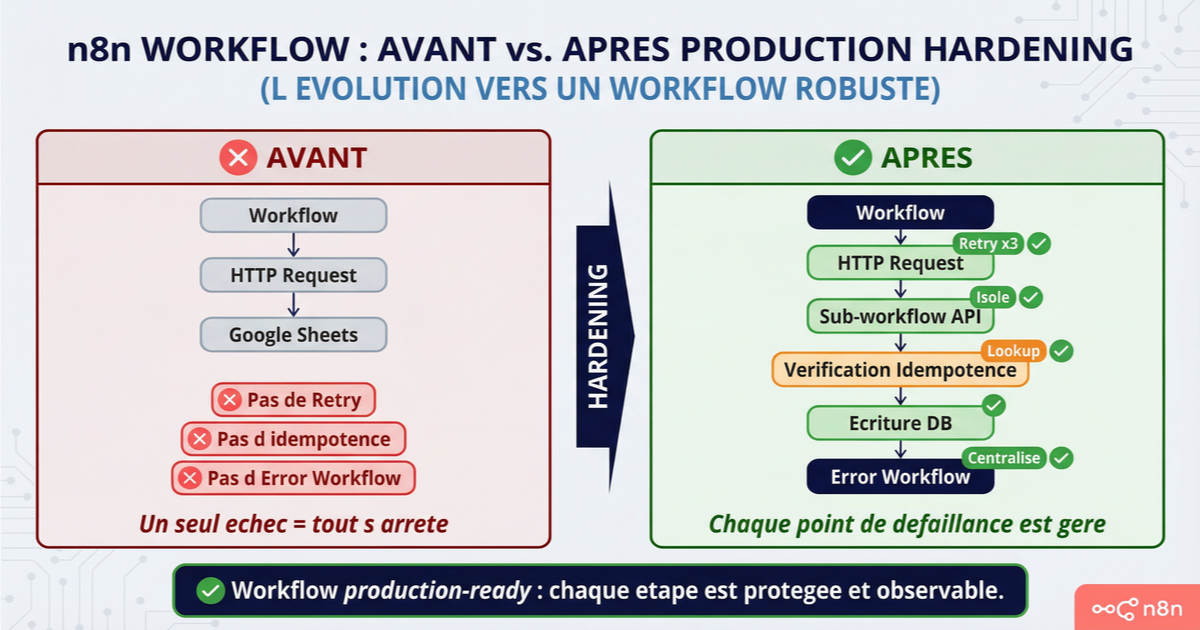
Chaque node qui appelle un service externe a un "Retry on Fail" configuré. 3 retries, 5 secondes d'intervalle minimum. Les nodes qui traitent des données utilisateur ont "Continue (using error output)" activé, avec la branche erreur câblée vers un logging ou une notification. Les opérations risquées sont isolées en sub-workflows pour contenir l'impact d'un échec. Les workflows qui créent des enregistrements (factures, leads, commandes) intègrent un contrôle d'idempotence — lookup avant écriture ou clé de déduplication. Un Error Workflow est assigné dans les settings du workflow principal. Le naming suit une convention claire qui distingue production, développement et sub-workflows. Un backup JSON du workflow est sauvegardé avant chaque modification significative (n8n n'a pas de version control natif).
Le test en conditions réelles est aussi important que la configuration. Désactivez volontairement un credential pour vérifier que votre error handling se déclenche. Envoyez des données malformées pour voir si votre batch processing les isole correctement. Simulez un timeout en pointant un HTTP Request vers un endpoint lent. L'error handling qui n'a jamais été testé ne fonctionne probablement pas.
L'error handling dans n8n est fonctionnel mais dispersé. Les briques sont là — "On Error", retry, Error Trigger, sub-workflows — et c'est à vous de les assembler en une architecture cohérente. La documentation officielle couvre chaque mécanisme individuellement sans vraiment adresser la question d'ensemble : comment tout ça s'articule quand vous avez 20 workflows en production qui tournent jour et nuit.
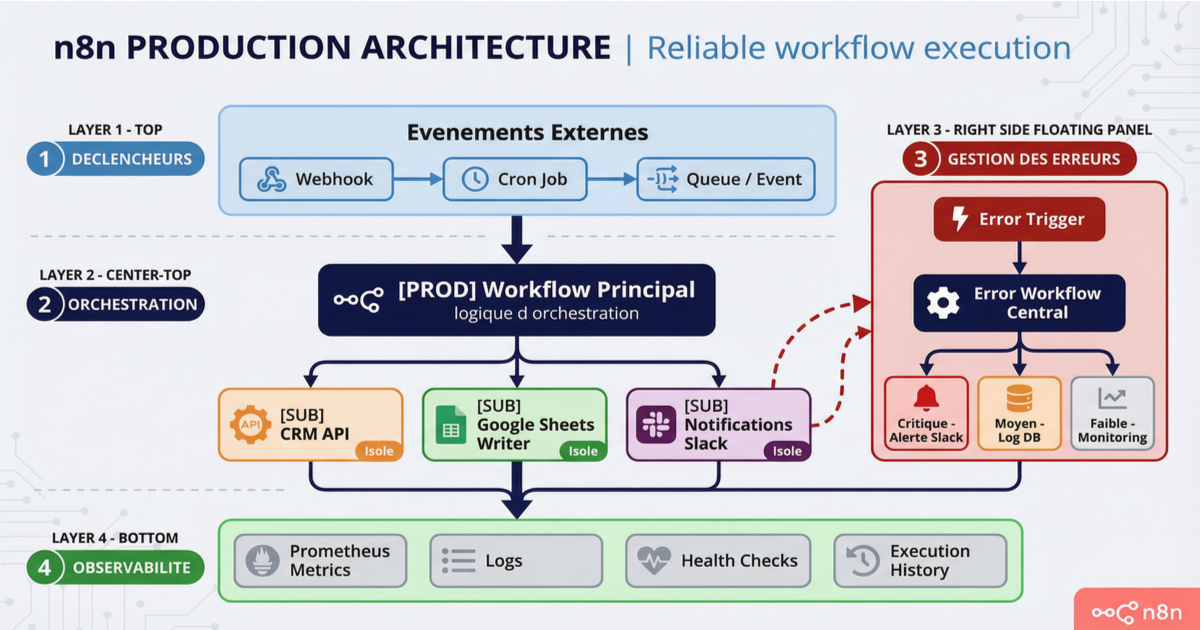
Si vous ne retenez que deux choses : un Error Workflow centralisé avec triage par criticité, et l'isolation systématique des appels externes en sub-workflows. Le reste — monitoring Prometheus, logging métier, health checks — vient ensuite selon votre volume et votre tolérance au risque.
Prochain article de la série : Sécuriser et maintenir n8n en production — comment verrouiller vos webhooks, automatiser vos sauvegardes, et sécuriser votre infrastructure.